
Before we dive into the details, though, let’s first understand why learnability is important in the context of supervised machine learning classification problems which is our current focus here at Brainome.
What is classification? Here are some examples: ball vs strike, good credit risk vs bad credit risk, dog vs cat vs horse vs cow, etc. For these types of problems, the most fundamental question is always: can I create an accurate and generalized model (classifier) from the data I have collected? Another way of saying this is: how learnable is my data? Because, fundamentally, the more “learnable” your data is, the better your classifier will be.
So what makes one data set learnable and another data set not learnable? Let’s take a look at a few examples.
Example A: 2, 4, 6, 8
If you’re given the set of numbers [2, 4, 6, 8] and asked to guess the next number in the sequence, what would your guess be? Most people would say 10. And the next number is 12 and the rule is “+2”. This is the epitome of a learnable data set — the explanatory rule (or pattern if you like) that governs is immediately obvious.
Interestingly, adding more instances to this data set does not make it more learnable. If you were given [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, etc], you would have still figured out the rule after analyzing the just first 4 numbers. At some point in every learnable data set, your learning must plateau. In other words, the explanatory rule has to settle at some point.
Example B: 6, 5, 1, 3
If we play the same game with [6, 5, 1, 3], then it’s a little more challenging. There is no obvious rule or pattern. And that’s because this data set consists of 4 numbers chosen at random. The overly clever readers out there may think there’s a pattern (-1, -4, +2, etc.) but we assure you that this data set is as random as [8, 6, 7, 5, 3, 0, 9] — the string of digits made famous by Tommy Tutone’s classic 80’s pop hit 🙂
The thing about Jenny’s number (and everyone’s phone number for that matter) is that it’s just a random sequence of digits with no rhyme or reason whatsoever (no rule). And here we have the epitome of an unlearnable data set. By definition, randomness is not learnable and the best one can do with a random data set (e.g., phone numbers) is to memorize it. Said another way, randomness (“unlearnability”) is the enemy of prediction.
Human Learning vs Machine Learning
The lead character in the Amazon Prime series “Mozart in the Jungle” is a symphony conductor whose life revolves around classical music. In one episode, he asks his audience: “Why do you call it ‘classical music’?” His point is: when the symphonies were first written and performed for audiences, they were known as just “music”. Similarly, there is a modern discipline called “machine learning” which some people associate with magical predictive powers. But, the reality is that computers learn exactly the same way that humans learn — which shouldn’t really be a surprise since humans invented computers … and machine learning.
So how exactly do humans learn? Well, there are 2 fundamental ways: (1) we memorize; or (2) we recognize patterns & rules and remember the patterns & rules. As explained above, some data sets can only be memorized because they are inherently random. Non-random data sets, however, don’t require memorization because rules can be extracted and used for prediction (i.e., learning occurs).
Compressible = Learnable = Generalization
In our “Memorization is Worst Case Generalization” article, we discuss two different strategies for teaching children how to multiply. One requires memorization. If we were to ask a child (or a computer) to “learn” multiplication by memorizing an ever growing multiplication table, that learner (human or digital) would eventually run out of memory. And short of having infinite memory (which is not possible), there would still be many multiplication problems that the memorization driven learner could not solve.
Alternatively, if we teach the learner a simple rule — multiplication is just adding the same number over and over again — then they would be able to solve an INFINITE number of multiplication problems while still having a lot of memory left over to learn other topics. And the memory footprint of a recursive program that adds numbers together to implement multiplication is infinitesimally small compared to the memory footprint of a 1 trillion row X 1 trillion column multiplication table. Simply put, multiplication is pretty easy to learn … as long as your learning strategy isn’t memorization.
So there’s clearly a relationship between compression and learnability. And if you’ve read “Memorization is Worst Case Generalization”, it’s now plainly obvious that the title of that article could (should ?) have been “Memorization is Worst Case Learnability”. FYI, the relationship between compression and learnability / generalization is explored in detail in this YouTube lecture.
The Punch Line (aka “I can learn that data set using X bits of memory”)
It’s probably safe to say that most adults know how to multiply. But, since we’re all unique, it’s probably also safe to assume that the multiplication model in each of our heads is slightly different and occupies a different amount of memory for everybody. Similarly, anyone who is 5 or older has a pretty general dog vs. cat classifier somewhere in their brain. Like the multiplication model, the dog vs. cat classifier is slightly different for everyone. What we cannot do today is measure the amount of memory the dog vs. cat classifier in your organic brain occupies (i.e., the number of neurons it took for you to learn the difference between dogs and cats).
What Brainome can do today is measure the amount of memory a machine learning model needs in order to learn an arbitrary data set. The details for how we do this are explained in this academic paper. Knowing how much memory is required to learn a data set is the key to measuring (quantifying) learnability.
If we ask ourselves, “What is the hardest thing in the world to learn?”, it should be pretty clear from Example B above that the answer is random data. Randomness can only be memorized — it cannot be learned. In fact, it is the opposite of learnable. If we can measure how much memory is needed to learn a random data set of arbitrary size and class balance, then we have our stake in the ground for determining learnability. If the same machine learning model requires less memory to learn your data set than is required to learn random data, then it’s a clear indication that your data isn’t random and there are rules & patterns that can be identified, learned and used for prediction, as depicted here:
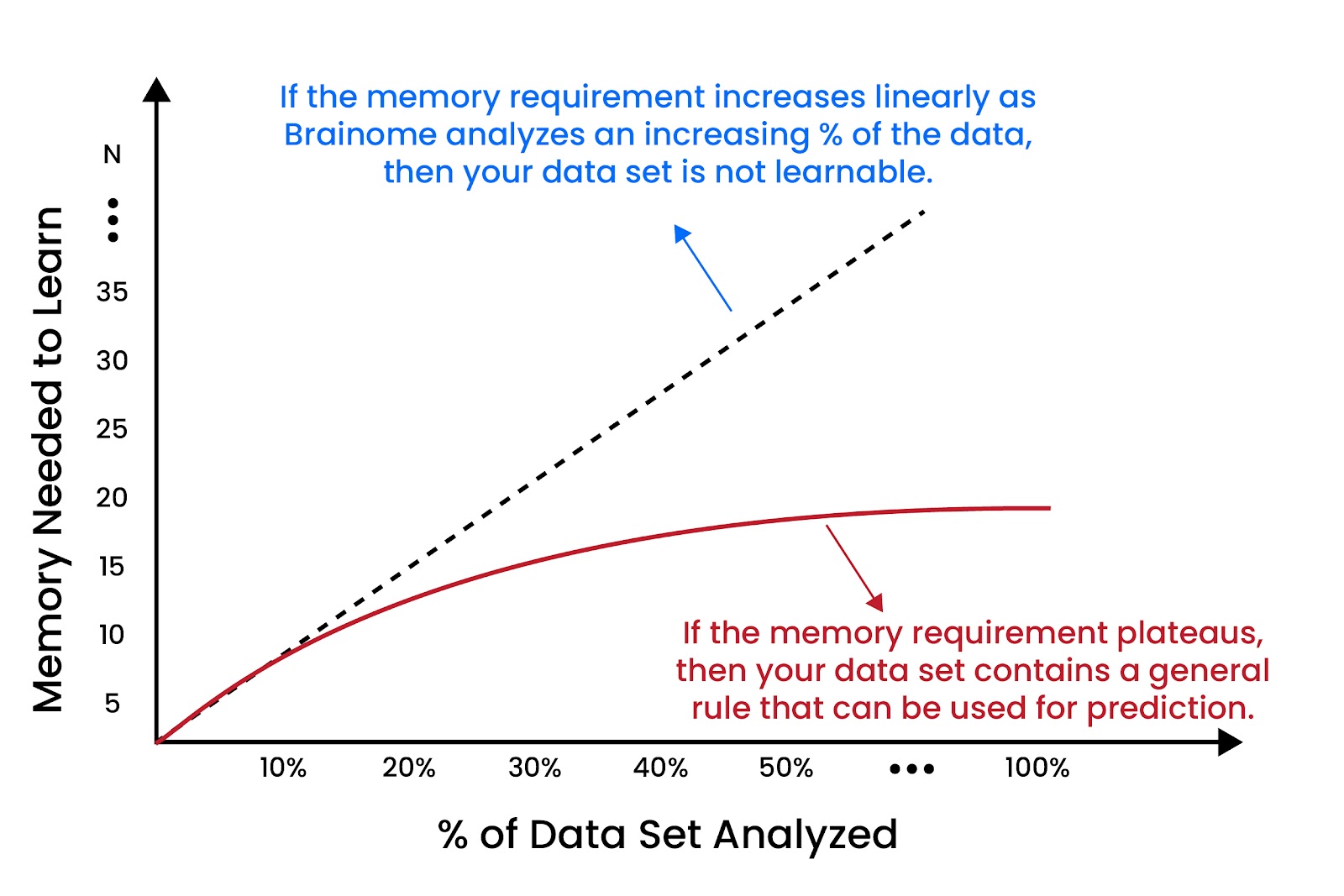
Epilogue
Hopefully, you now have a better understanding of learnability and why it is the fundamental principle behind Brainome’s approach to machine learning.
If not, we can at least offer one more example of irony:

P.S. If you’d like to measure the learnability of your own data sets, please visit the Brainome Web Demo.

